Consequence-Guided Information Extraction for Predicting Central Bank Communication’s Effect
 We harness RL towards domain-professional-level document understanding
We harness RL towards domain-professional-level document understandingAbstract
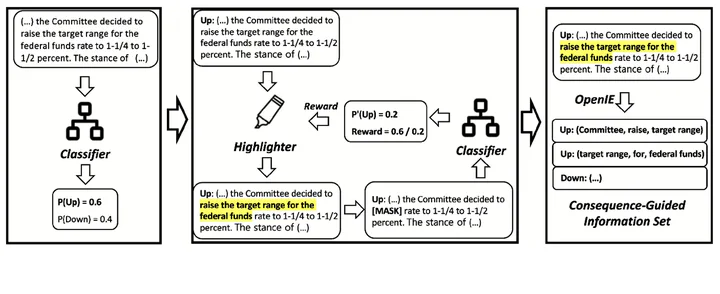
Predicting how financial markets respond to central bank communications is a key challenge in economics and finance. However, central bank communications are relatively rare events, making it challenging to apply standard data science methods. To address this issue, we focus on the characteristics of central bank communications, especially those from the FOMC, which typically consist of a short statement and a full-length minute. We introduce a consequence-guided information extraction system that utilizes state-of-the-art natural language processing and reinforcement learning techniques. Utilizing the pre-trained BERT prediction as a reward signal, we train a model to highlight the most influential text span in FOMC minutes. Then, we apply the Open Information Extraction system to obtain the structured information tuples from the highlighted span. By using it as a feature extractor, we achieve 77-86% accuracy in predicting the future direction of the various economic variables, compared to 43–66% accuracy from standard natural language processing methods such as bag-of-words, topic modeling, and fine-tuned BERT. Our study shows how a model with limited capacity can be improved when combined with a proper structure, especially in a data-scarce situation.
Donghun Lee
Associate Professor
Connecting artificial intelligence and mathematics, in both directions.