 Sensitivity analysis of ORKG shows graceful exploitation-exploration tradeoff
Sensitivity analysis of ORKG shows graceful exploitation-exploration tradeoffAbstract
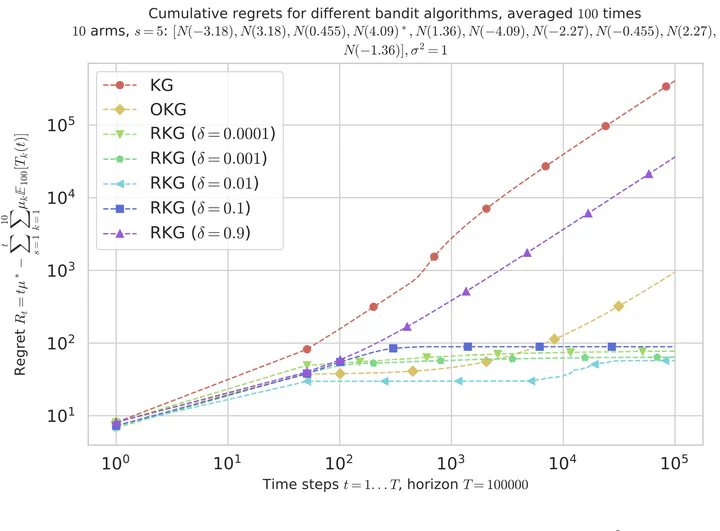
We introduce a simple and effective regularization of knowledge gradient (KG) and use it to present the first sublinear regret bound result for KG-based algorithms. We construct online learning with regularized knowledge gradients (ORKG) algorithm with independent Gaussian belief model, and prove that ORKG algorithm achieves sublinear regret upper bound with high probability facing bounded independent Gaussian multi-armed bandit (MAB) problems. The theoretical properties of regularized KG and ORKG algorithm are analyzed, and the empirical characteristics of ORKG algorithm are empirically validated with MAB benchmark simulations. ORKG algorithm shows top-tier performance comparable to select MAB algorithms with provable regret bounds.
Donghun Lee
Associate Professor
Connecting artificial intelligence and mathematics, in both directions.